For you always, sir.
每次与公司同事和实验室组员谈及对话系统这个话题,我的内心都非常激动,因为太爱这个领域,或许是受到了钢铁侠管家“贾维斯”的影响,毕竟我最爱的漫威英雄是Iron Man。在研究和工作的业余时间,我也在继续研究这个领域,在知识图谱、自然语言理解、自然语言生成、闲聊系统都有所涉猎。本文主要是对Dialogue System及其相关技术进行介绍。
相关工程实现可参考这个repo
1.对话系统概述
根据应用领域类型可将对话系统划分为两种类型:开放域对话系统与限定域对话系统,其中开放域对话系统大多谈及的是闲聊系统,限定域对话系统大多谈及的是针对专业领域的问答系统,如KBQA、KGQA。
根据任务类型可将对话系统划分为以下类型:
- Retrieval_QA/检索式问答
- KBQA/基于知识库的问答
- KGQA/知识图谱问答
- MRC/机器阅读理解
- Chat_System/闲聊系统
在技术方面,一个完美的对话系统应该如下图所示,包括NLU(自然语言理解)模型、DST(对话状态追踪)模块、DPL(对话策略学习)模块以及NLG(自然语言生成)模块。然而目前大多数对话系统仅采用了NLU模块,对于其它三个模块并未深入涉及。
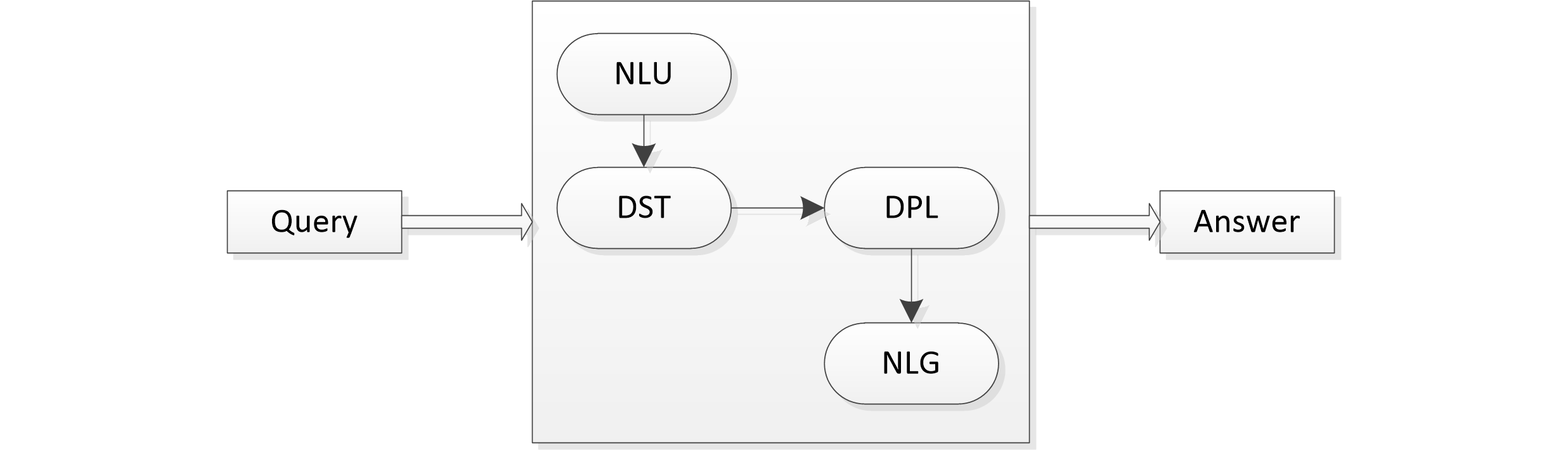
(1)NLU-自然语言理解模块
NLU模块的主要任务是将用户输入的自然语言映射为用户的意图和对应的槽位值,即该模块将用户输入语句Xn解析成对应的用户动作Un。该模块主要涉及两个技术:意图识别和槽位填充,对应用户动作的两个结构化参数:意图和槽位。
意图识别,也被称为SUC(Spoken Utterance Classification),例如“我想订火车票”,其意图为“购票”,再如之前介绍的法律知识图谱构建文中的法律问题“代位继承的定义”,其意图为“查定义”。
槽位填充,也被称为Slot Filling。一个意图往往对应着多个槽位,例如“购票”意图有“出发日期”、“出发站”、“到达站”等必要槽位。
在实际业务中,意图识别通常被当做分类任务来做,而槽位填充会被转化为序列标注任务。
(2)DST-对话状态追踪模块
DST模块是以当前的用户动作Un、前n-1轮的对话状态和相应的系统动作作为输入,输出是判定的当前对话状态Sn。即:根据当前的对话来给出系统判断的对话状态。
在该模块中,对话状态的表示通常包括3个部分:
- 目前为止的槽位填充情况;
- 本轮对话过程中的用户动作;
- 对话历史。
在实际业务中,主要是基于序列标注模型来进行状态跟踪。
(3)DPL-对话策略学习模块
DPL模块以DST模块判定的对话状态Sn作为输入,输出为系统动作An。目前绝大多数都是基于规则来实现DPL,也就是人工设计有限状态自动机。
有限状态自动机有两种表示方式:
以点表示数据(槽位状态),以边表示操作;
以点表示操作(系统动作),以边表示数据(槽位状态)。
在实际业务中对比发现,后一种表示方式以系统动作为核心,设计方式更为简洁,并且易于工程实现。
通常系统动作的定义有问询、确认和回答3种模式。问询的目的是了解必要槽位缺失的信息;确认是为了解决容错性问题,填槽之前向用户再次确认;而回答则是最终回复,意味着任务和有限状态自动机工作的结束。
下面将给出一个具体示例,看看DPL模块的有限状态自动机究竟是怎么工作的。
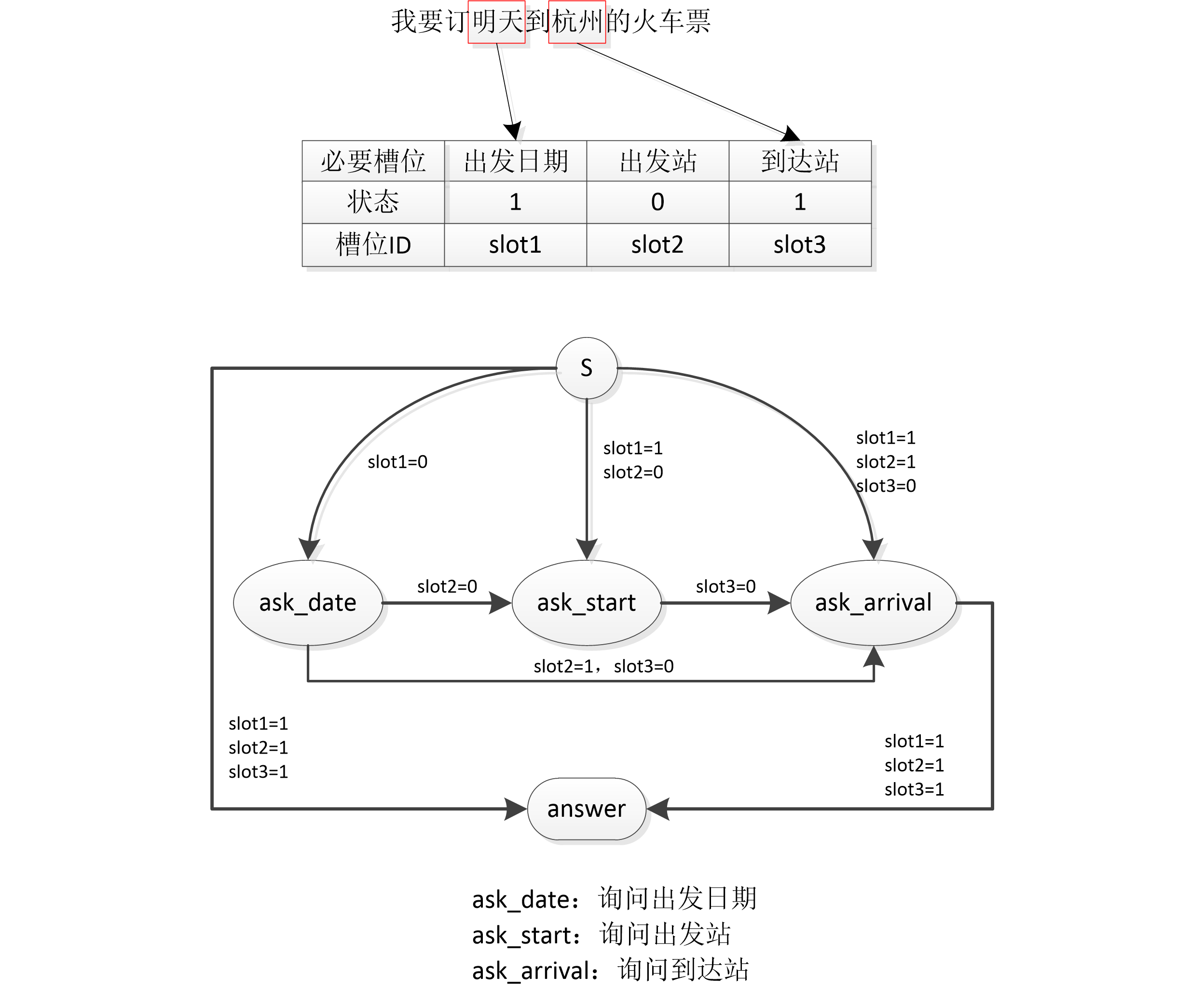
如上图所示,针对用户问题“我要明天到杭州的火车票”,其意图为“购票”,该意图下有三个必要槽位:“出发日期”、“出发站”、“到达站”,目前假设经过NLU模块、DST模块已经将其意图和槽位识别出来,发现“出发站”这个槽位缺失,于是根据上面的有限状态自动进的规则找到“slot1=1, slot2=0”这个路线,生成系统动作ask_start,进而执行“问询”模式。
(4)NLG-自然语言生成模块
NLG模块以DPL模块的系统动作作为输入,输出是系统对用户输入Xn的回复Yn。目前,NLG模块广泛采用基于规则的方法,进而根据规则将各个系统动作映射成自然语言表达。
下面给出示例。
| 系统动作 | 系统回复 |
|---|---|
| ask_data | “请告诉我出发时间” |
| ask_start | “请告诉我出发地点” |
| ask_arrival | “请告诉我到达地点” |
| answer(date=$date,start=$start,arrival=$arrival) | “已为您购买$date,从$start到$arrival的火车票” |
2.检索式问答
目前市场上大多问答系统仍是检索式问答模式,即给定用户问题,基于检索的方式匹配到最相似的问题,而后将这个最相似的问题所对应的答案返回给用户。
本仓库中提供了最常见的几种模型,也是实际工程上非常适用的模型。(因实践数据是公司内部的,暂无法提供实例数据)。
unsupervised_method:提供了两种无监督式的相似度计算方法来实现FAQ,tfidf和jaccard编辑距离。
dnn_dssm:基于tf-idf+dnn的dssm模型。
lstm_dssm:基于词向量+lstm的dssm模型。
lstm_siamese:基于词向量+lstm的siamese模型。
2.1无监督方法
(1)TF-IDF
TF-IDF为TF与IDF的乘积,核心思想:一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章。
词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)公式如下所示:

逆文档频率(inverse document frequency,IDF)主要思想是:如果包含词条w的文档越少, IDF越大,则说明词条具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。公式如下:
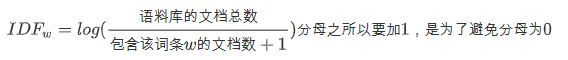
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
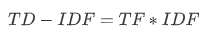
(2)jaccard系数
Jaccard系数主要用于计算样本间的相似度。公式如下:
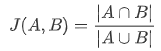
Jaccard系数主要的应用的场景有 1.过滤相似度很高的新闻,或者网页去重 2.考试防作弊系统 3.论文查重系统
2.2深度语义匹配模型
(1)DSSM模型
DSSM,Deep Structured Semantic Models,原理很简单,通过搜索引擎里 Query 和 Title 的海量的点击曝光日志,用 DNN 把 Query 和 Title 表达为低维语义向量,并通过 cosine 距离来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低维语义向量表达。
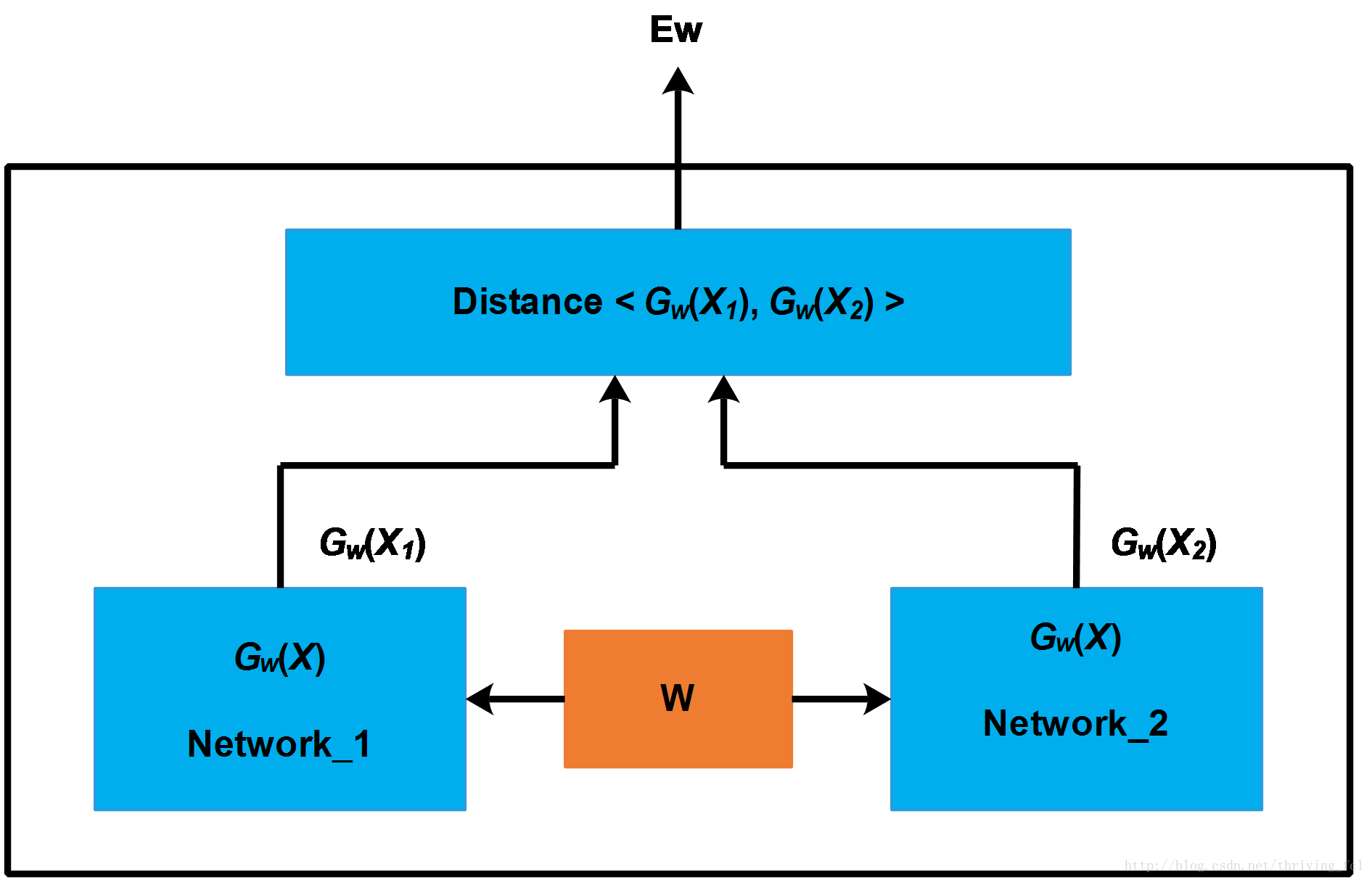
(2)Siamese模型
Siamese Network 是一种神经网络的框架,而不是具体的某种网络,就像seq2seq一样,具体实现上可以使用RNN也可以使用CNN。简单的说,Siamese Network用于评估两个输入样本的相似度。网络的框架如下图所示。
3.基于知识库的问答
KBQA(基于知识库的问答)其实就是检索式问答的扩展版本,因为KBQA将问答领域限制在了某个专业领域,问答对质量较高,如下图所示的例子,知识库中还带了领域类别。

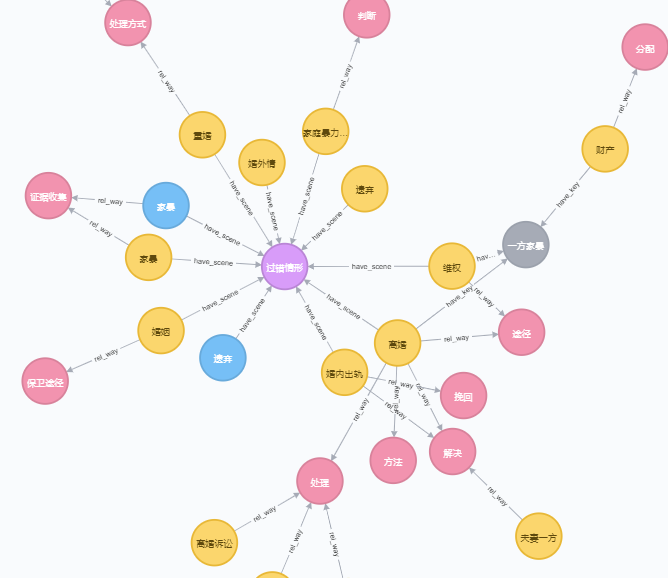
4.知识图谱问答
KGQA(知识图谱问答)主要是针对图谱中的知识点进行检索。构成知识图谱的元素为三元组形式<主实体,关系,客实体>或者<实体,属性,属性值>。
如下图所示:
5.机器阅读理解
待续
6.闲聊系统
待续